
I trust my skills because they have evals
“In God we trust; all others must bring data.” — W. Edwards Deming
There are hundreds of skills for Claude Code, but I only use a few.
The reason is simple: I evaluate them to make sure they add something beyond what the model already does by default.
Installing a third-party skill is easy. You test it twice, it seems to work, and you call it good.
The problem is that “seems to work” does not mean it adds anything. The model could do the same thing just as well without the skill, and you would never know.
Measure instead of believe
I started using the evaluation framework from skill-creator, the Anthropic skill designed to create, iterate, and measure skills. Now every skill I build or test has an eval suite.
The cycle is simple:
- Design the tests you want the skill to pass.
- Run the task without the skill.
- Run the same task with the skill.
- Compare pass rate, tokens, time.
Each iteration of the skill is measured against the previous one. There is no “I think it works better.” There are numbers.
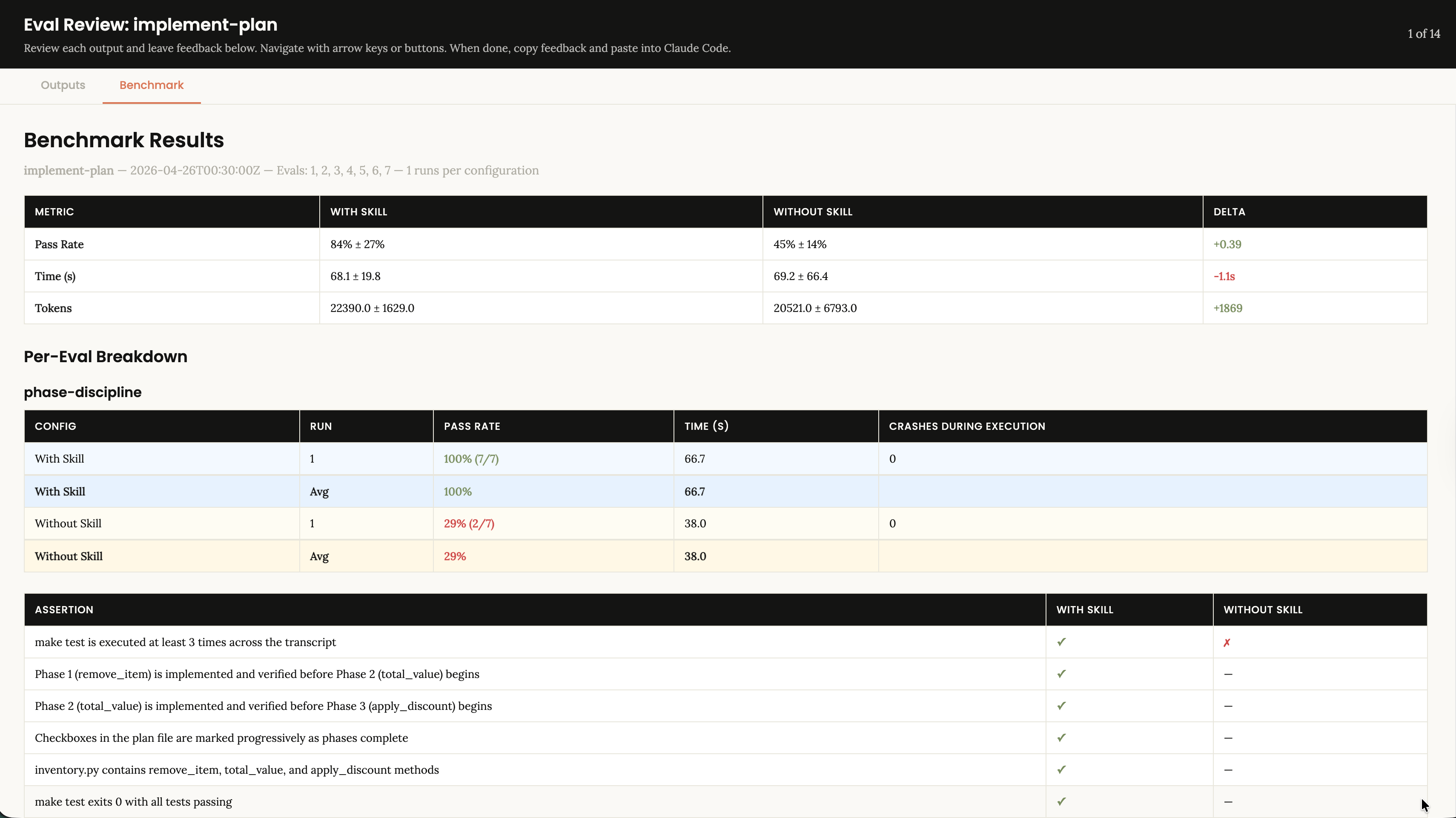
What the numbers tell you
A skill that seems useful sometimes makes results worse.
Another that seemed trivial saves 40% of tokens.
A prompt change that took 5 minutes doubles the pass rate.
None of this would be visible without measuring.
Testing for your skills
You would not deploy code to production without tests or metrics. But the skills that guide the AI to write all that code, we use them because “they work for me.” It is the “works on my machine” of the agent era.
Evals are the tests for your skills. If you do not have them, you do not know if they work. You only believe they work.
If you want more detail, you can see how I do it in stepwise-dev, my Claude Code plugin, or you can reach me on LinkedIn, X, Bluesky, or GitHub.