
Me fío de mis skills porque tienen evals
“In God we trust; all others must bring data.” — W. Edwards Deming
Hay cientos de skills para Claude Code, pero yo acabo usando muy pocas.
La razón es muy sencilla, las evalúo para garantizar que aportan algo más allá de lo que el modelo ya hace por defecto.
Instalar una skill de terceros es fácil. La pruebas dos veces, parece que va bien, y la das por buena.
El problema es que “parece que va bien” no significa que aporte nada. El modelo podría hacer lo mismo igual de bien sin la skill, y tú no lo sabrías.
Medir en vez de creer
Empecé a usar el framework de evaluación de skill-creator, la skill de Anthropic pensada para crear, iterar y medir skills. Ahora cada skill que desarrollo o que pruebo tiene una suite de evals.
El ciclo es simple:
- Diseño las pruebas que quiero que pase esa skill.
- Ejecuto la tarea sin la skill.
- Ejecuto la misma tarea con la skill.
- Comparo pass rate, tokens, tiempo.
Cada iteración de la skill se mide contra la anterior. No hay “creo que funciona mejor”. Hay números.
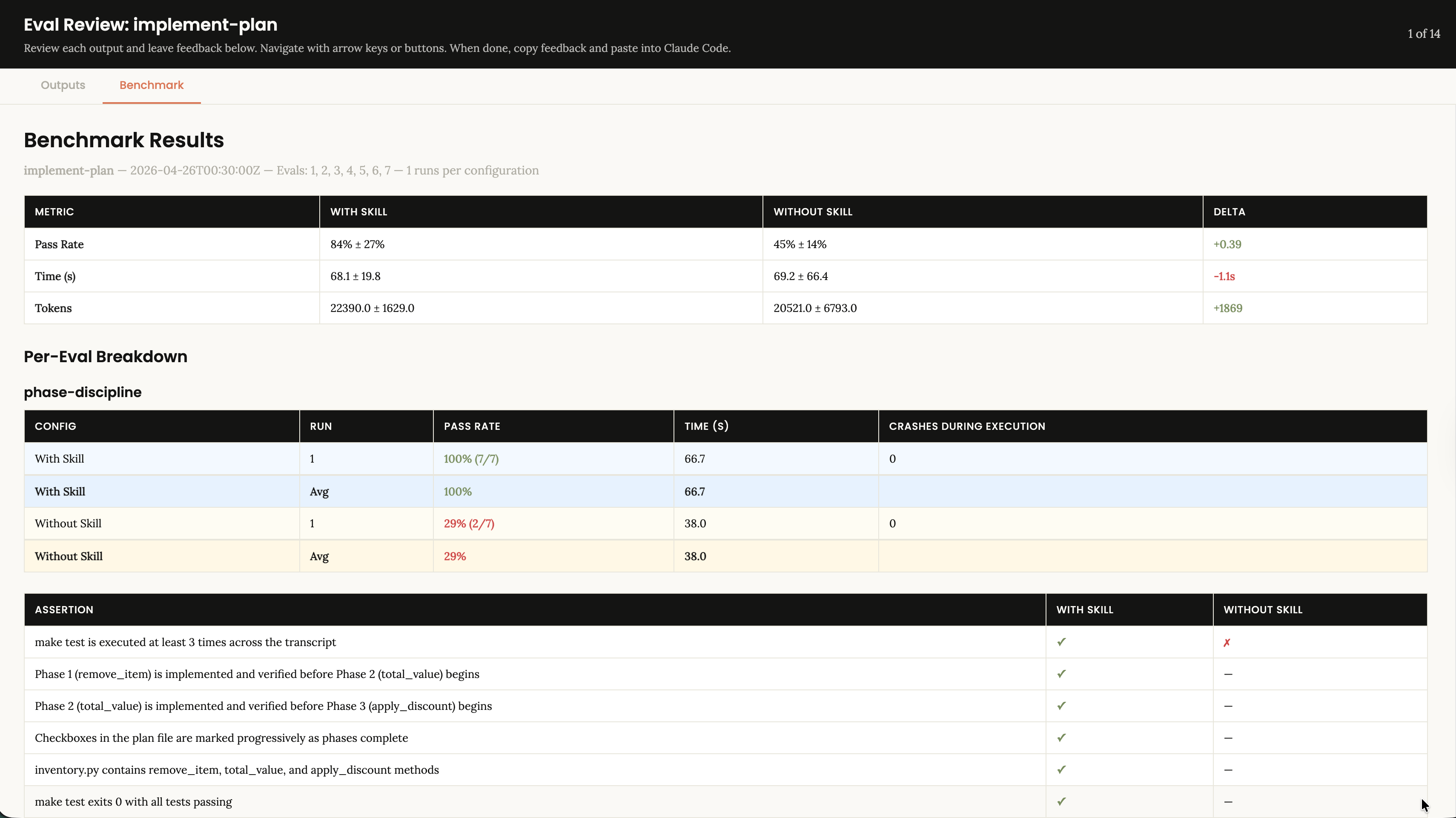
Lo que los números te dicen
Una skill que parece útil a veces empeora los resultados.
Otra que parecía trivial ahorra un 40% de tokens.
Una refactorización del prompt que tardaste 5 minutos dobla el pass rate.
Nada de esto lo sabría sin medir.
Testing para tus skills
No desplegarías código a producción sin tests o sin métricas. Pero las skills que guían a la IA para desarrollar todo ese código las usamos porque “a mí me van bien”. Es el “en mi máquina funciona” de la era de los agentes.
Las evals son los tests de tus skills. Si no los tienes, no sabes si funcionan. Solo crees que funcionan.
Si quieres más detalle, puedes ver cómo lo hago en stepwise-dev, mi plugin para Claude Code, o puedes escribirme directamente en LinkedIn, X, Bluesky o GitHub.