
Tu CLAUDE.md no funciona (sin Context Engineering)
“Context engineering over prompt engineering” - Andrej Karpathy
Ya has visto todos los tutoriales de Claude Code.
Has creado tu flamante CLAUDE.md y tienes unas buenas reglas de arquitectura y diseño. ¡A desarrollar!
Pero cuando Claude Code lleva un rato haciendo cambios empieza a olvidar tus reglas y ya no desarrolla como necesitas.
El problema no son tus reglas. El problema es que no estás controlando el contexto.
¿Por qué tener un CLAUDE.md no es suficiente?
Mi CLAUDE.md define principios claros y sólidos. Pero hay dos problemas:
1. Claude Code puede ignorar tu CLAUDE.md
Como explica HumanLayer en su artículo sobre CLAUDE.md, Claude Code inyecta un recordatorio de sistema que dice explícitamente:
<system-reminder>
IMPORTANT: this context may or may not be relevant to your tasks.
You should not respond to this context unless it is highly relevant to your task.
</system-reminder>
Claude ignorará tu CLAUDE.md si decide que no es relevante para la tarea actual. Cuantas más instrucciones específicas o “hotfixes” temporales tengas, más probable es que las ignore.
Solución: Mantén solo principios universalmente aplicables. Evita instrucciones de contexto específico.
2. Las mejores reglas no sirven con demasiado contexto
Lo importante no son las ventanas de contexto, son las ventanas de atención
Los fabricantes de LLMs anuncian ventanas de contexto enormes. Claude 3.5 Sonnet acepta 200k tokens. Gemini 1 millón. Suena impresionante.
Pero hay que diferenciar entre cuánto contexto aceptan (la ventana de contexto) y cuánto contexto pueden procesar de forma eficaz (la ventana de atención).
La ventana de contexto vs la ventana de atención
Los fabricantes no publican información de sus ventanas de atención para no revelar detalles de implementación de sus arquitecturas. Pero la comunidad ha intentado buscar el tamaño de la ventana de atención de forma empírica. Probando, probando y probando. En todas estas pruebas se demuestra que la ventana de atención es menor que la ventana de contexto.
| Modelo | Ventana de contexto | Ventana de atención | Fuente |
|---|---|---|---|
| GPT-4 Turbo | 128k tokens | ~64k tokens (50%) | RULER Benchmark |
| Claude 3/3.5 | 200k tokens | No he encontrado datos | Anthropic: “LLMs lose focus with long contexts” |
| LLaMA 3.1 | 128k tokens | ~32k tokens (25%) | Evaluaciones RAG Databricks |
| Mistral 7B | 32k tokens | ~16k efectivos (50%) | Benchmark RULER |
Las pruebas demuestran que después del 50-60% de la ventana de contexto, la precisión cae entre 20-50% dependiendo del modelo.
Después de varios meses trabajando con Claude Code, mi flujo de trabajo habitual era:
- Media hora de productividad espectacular, Claude trabaja de forma impecable siguiendo mi
CLAUDE.md - 45 minutos después: “Claude, así no, recuerda tu
CLAUDE.md”. Pero empieza a ignorar mis reglas de diseño y el contexto del proyecto: ¿Por qué crea un nuevo servicio si le pedí usar el existente? ¿Por qué no ha implementado tests? - 1 hora después: Claude Code me va a compactar el contexto automáticamente. ¿Seguiré por encima del 60%? ¿Hago
/cleary le explico todo otra vez? ¿Sigo así y me arriesgo a que siga ignorando mis reglas? - 2 semanas después: “¿Dónde guardé esa investigación de autenticación de la semana pasada?” -> Se la tengo que pedir de nuevo desde cero.
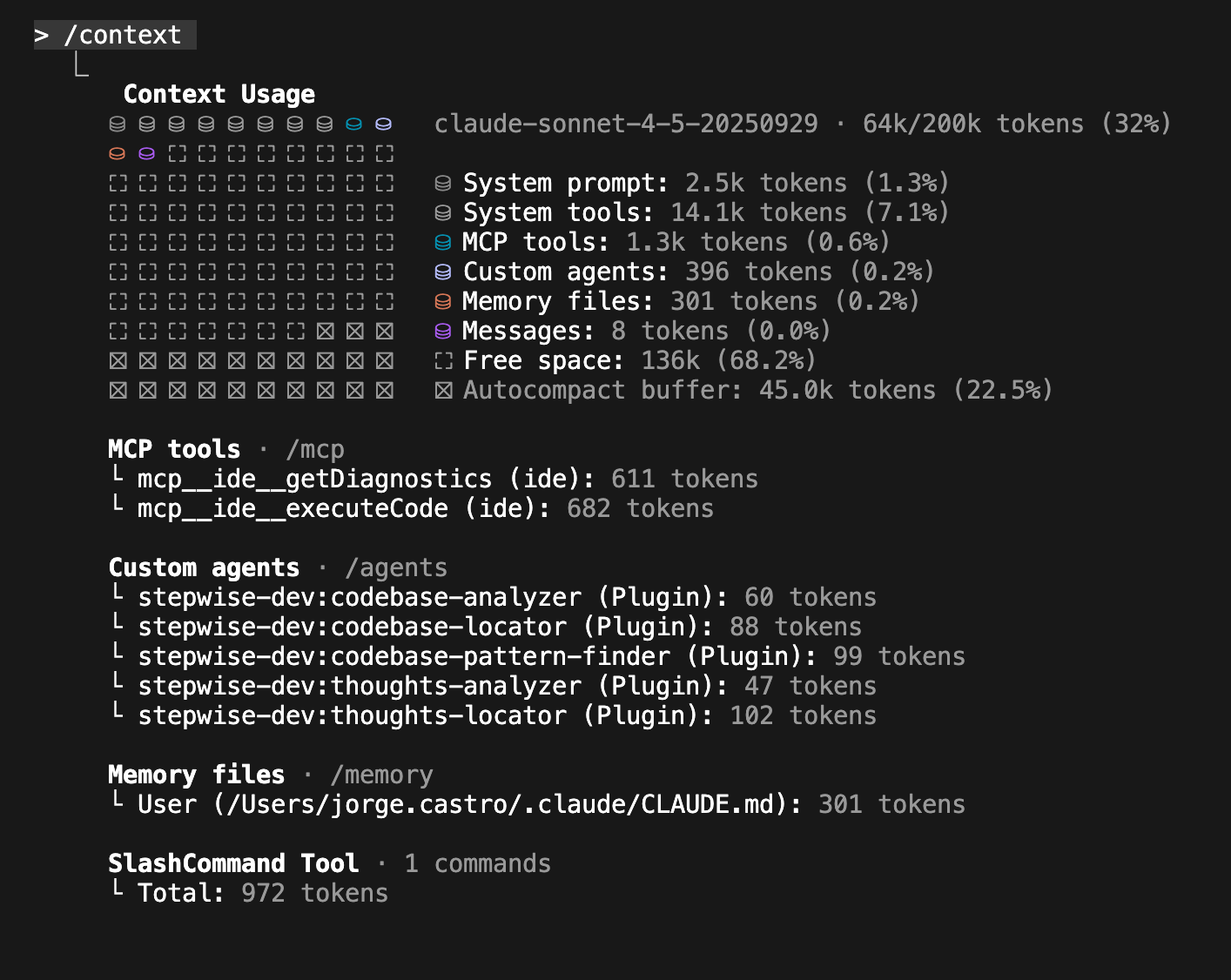
Este es mi contexto de Claude Code en una sesión nueva y limpia. De inicio ya está al 32% 😱:
Entonces encontré el marco “Frequent Intentional Compaction” (FIC) desarrollado por Dex Horthy y HumanLayer. Este marco propone un flujo de trabajo estructurado en fases (Research -> Plan -> Implement -> Validate) para mantener el contexto controlado.
He creado el plugin stepwise-dev para automatizar e implementar este flujo de trabajo FIC en Claude Code, manteniendo el contexto por debajo del 60% de forma sistemática.
El marco FIC (Frequent Intentional Compaction)
Como explica Dex Horthy en su charla sobre Context Engineering, el problema de contexto se resuelve con un flujo de trabajo estructurado:
“The key is to separate research, planning, and implementation into distinct phases with frequent intentional compaction.”
El marco FIC propone 4 fases independientes:
- Research: Investigación sin implementación
- Plan: Diseño iterativo antes de código
- Implement: Ejecución por fases
- Validate: Verificación sistemática
Entre cada fase, se hace limpieza intencional del contexto (/clear), pero el conocimiento persiste en archivos estructurados.
Stepwise-dev automatiza este flujo de trabajo FIC, proporcionando comandos específicos para cada fase y gestionando automáticamente la persistencia del conocimiento en el directorio thoughts/.
¿Cómo implementa el marco FIC stepwise-dev?
La solución no es escribir mejores prompts. Es estructurar tu flujo de trabajo para mantener el contexto controlado.
Stepwise-dev implementa las 4 fases del marco FIC mediante comandos específicos. Cada fase empieza con contexto limpio.
Research: Investiga sin implementar (/stepwise-dev:research_codebase)
El problema: pides a Claude “investiga cómo funciona X”. Claude carga 30 archivos, analiza todo, y terminas con 65% de contexto lleno de información que ya no necesitas.
/stepwise-dev:research_codebase "How does authentication work in this project?"
/clear
stepwise-dev lanza hasta 5 agentes especializados en paralelo (codebase-locator, codebase-analyzer, pattern-finder…) y genera un documento en thoughts/shared/research/.
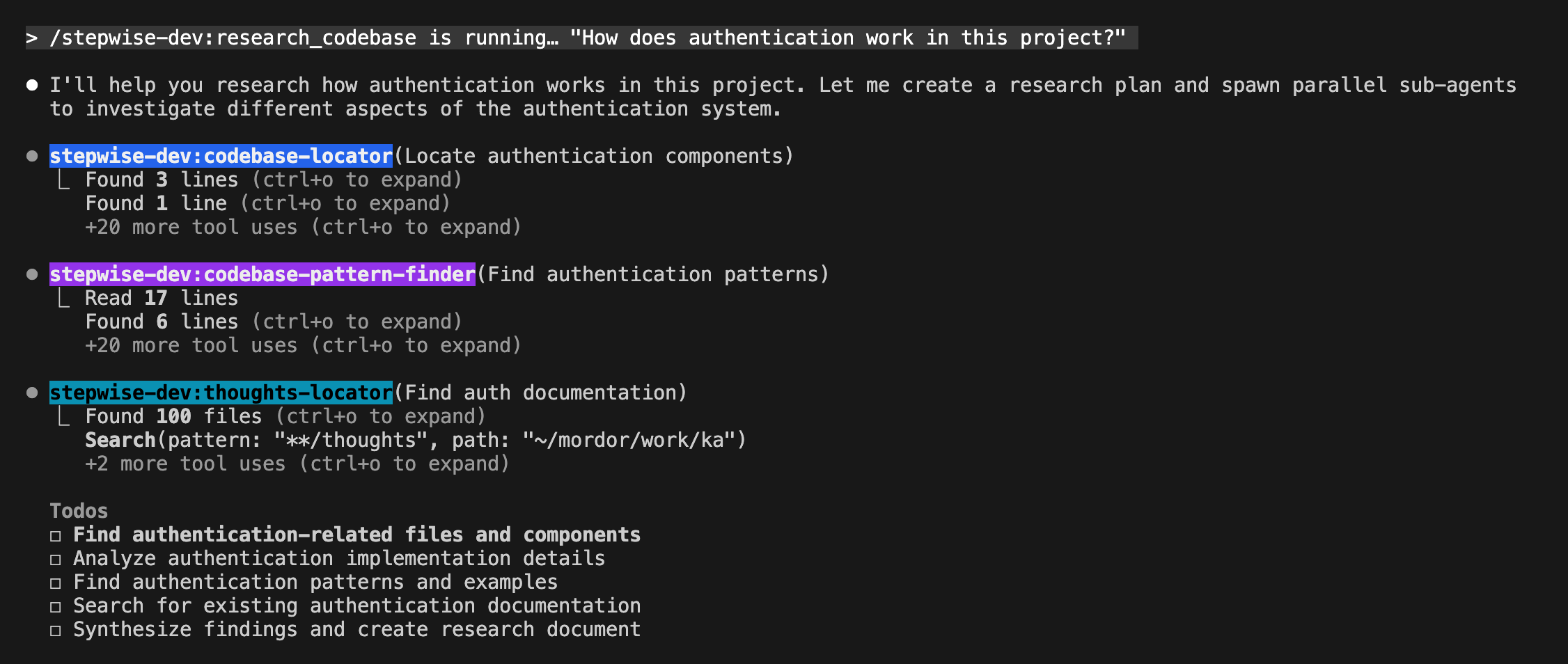
Cuando stepwise-dev termina la investigación, te guía en los siguientes pasos (también lo hacen el resto de comandos.)
Y este es mi contexto después del research en una carpeta con 7 proyectos que interactúan entre ellos pero están implementados con diferentes tecnologías (Astro, Java, Python):
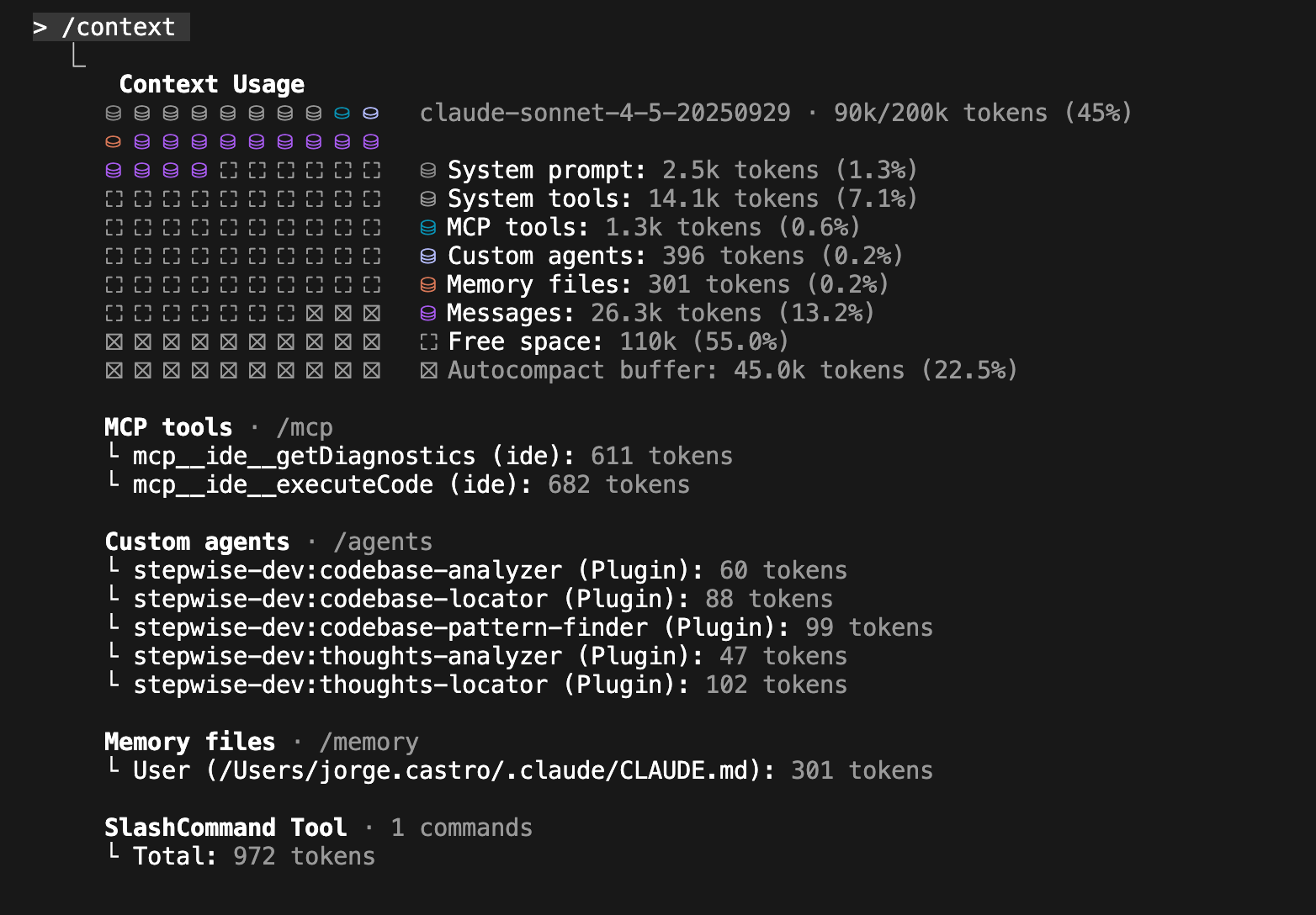
Después del /clear, conocimiento persistente. Contexto limpio.
Plan: Diseña antes de implementar (/stepwise-dev:create_plan)
Como dice Dex Horthy en Context Engineering SF: Advanced Context Engineering for Agents:
“A bad line of code is… a bad line of code. But a bad line of a plan could lead to hundreds of bad lines of code.”
Revisar 200 líneas de plan es más fácil que revisar 2000 líneas de código.
/stepwise-dev:create_plan @thoughts/shared/research/2025-11-15-auth.md Añade la autenticación entre servicios
/clear
# Opcional: iterar el plan
/stepwise-dev:iterate_plan @thoughts/shared/plans/2025-11-15-auth.md Añade soporte para refrescar tokens y la gestión de la expiración
/clear
Claude crea un plan estructurado en fases. Tú iteras las veces que quieras hasta que el plan sea sólido.
Recuerda que he lanzado /create_plan en una carpeta con 7 proyectos que interactúan entre ellos pero están implementados con diferentes tecnologías (Astro, Java, Python):
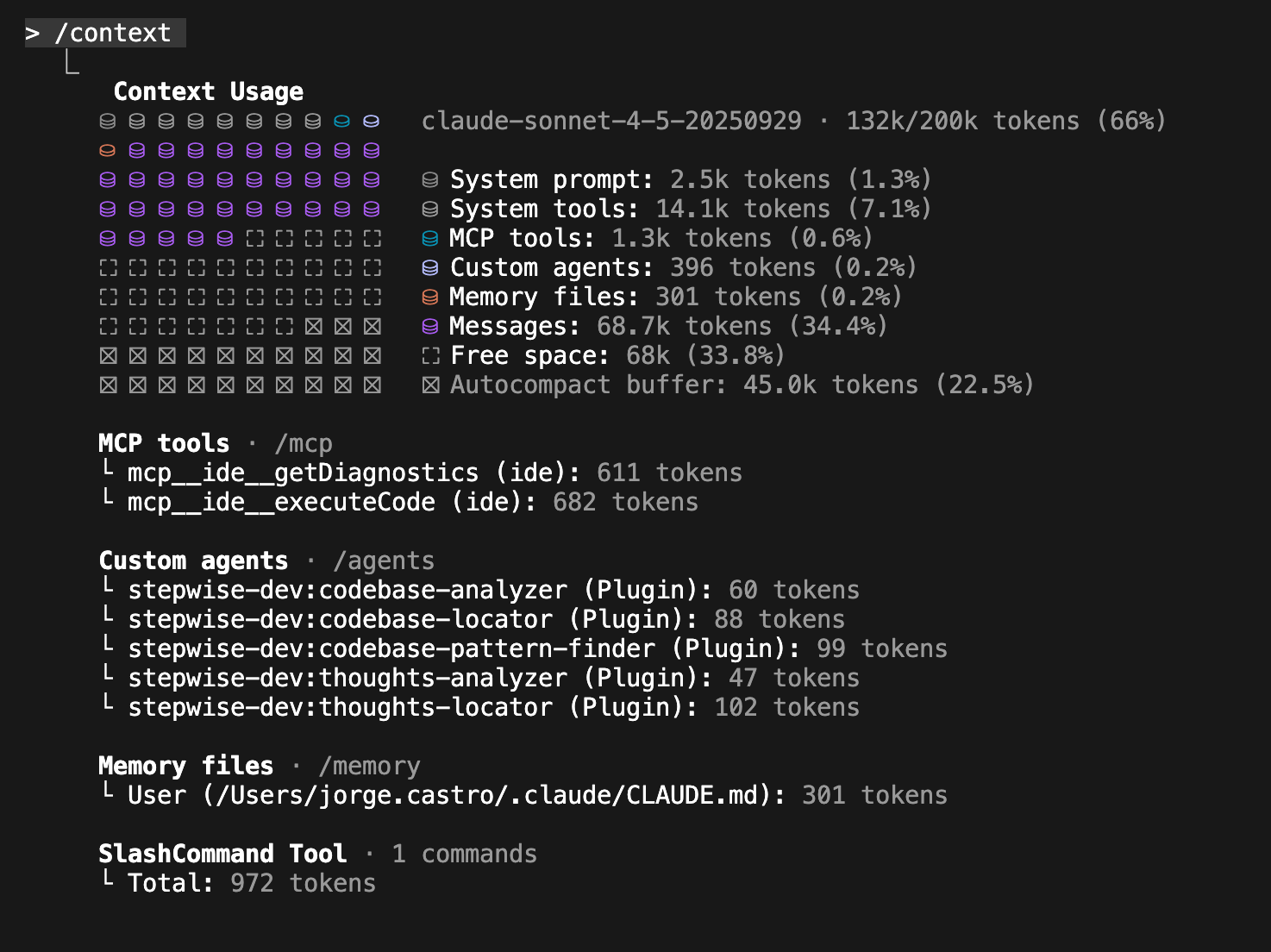
Implement: Implementa las fases de una en una (/stepwise-dev:implement_plan)
Stepwise-dev te permite implementar el plan completo. El problema es que seguramente hagas crecer el contexto más allá del 60%.
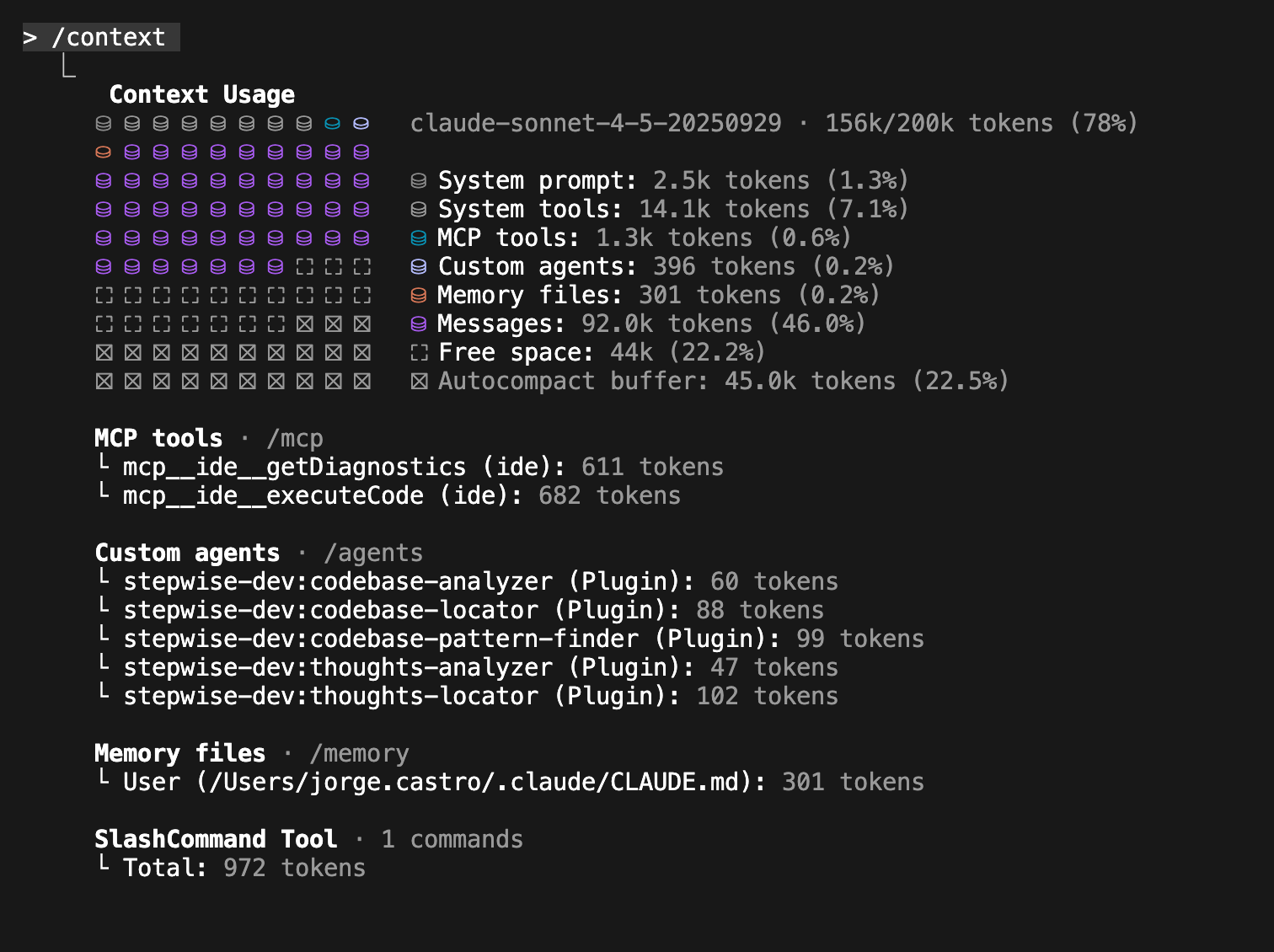
Por eso es importante ejecutarlo por fases:
/stepwise-dev:implement_plan @thoughts/shared/plans/2025-11-15-oauth.md Phase 1 only
/clear
Claude Code lee el plan completo, implementa solo UNA fase, ejecuta tests, y espera tu confirmación.
/stepwise-dev:implement_plan @thoughts/shared/plans/2025-11-15-oauth.md Phase 2 only
/clear
Resultado: El contexto nunca supera el 60% en proyectos pequeños/medianos y se queda muy cerca del 60% en proyectos grandes. El código es coherente porque cada fase tiene el contexto limpio.
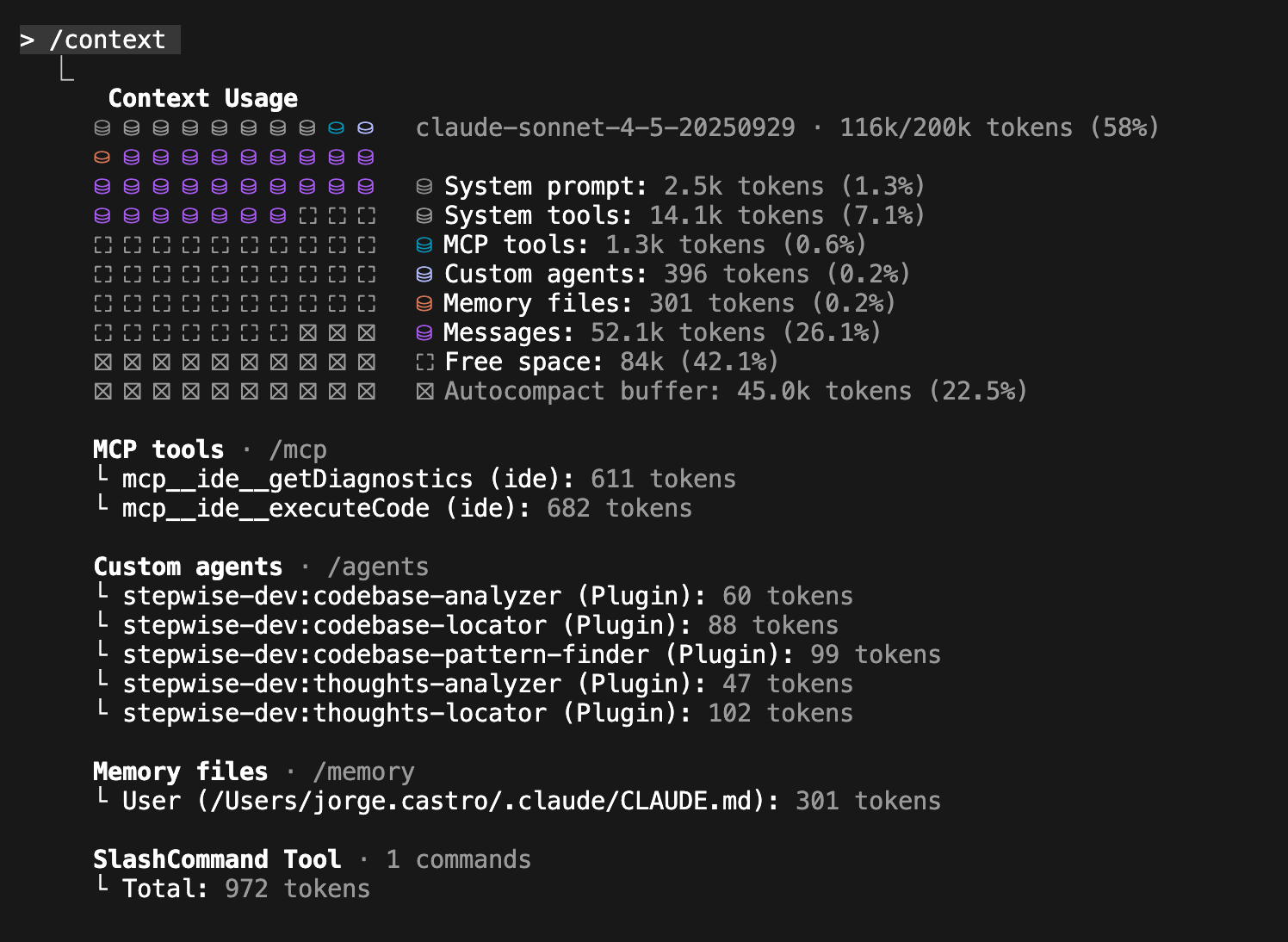
Validate: Verifica sistemáticamente (/stepwise-dev:validate_plan)
/stepwise-dev:validate_plan @thoughts/shared/plans/2025-11-15-oauth.md
/clear
Claude verifica que todo está implementado: todas las fases completadas, tests pasando, código coincide con el plan, sin desviaciones no documentadas.
¿Quieres probarlo?
Instala stepwise-dev y úsalo en tu siguiente sesión de trabajo.
# En Claude Code
/plugin marketplace add nikeyes/stepwise-dev
/plugin install stepwise-dev@stepwise-dev
# Reinicia Claude Code
Lo que realmente cambia con Stepwise-dev
He usado Claude Code durante meses antes de crear stepwise-dev.
El problema no era saber escribir código mantenible con Claude Code. El problema era gestionar bien el contexto.
La diferencia fundamental es el directorio thoughts/:
La carpeta /thoughts es un cerebro externo para Claude Code. Cada fase produce conocimiento reutilizable por Claude Code, sus agentes, otras sesiones o humanos.
Con stepwise-dev:
- Research -> Se guarda en
thoughts/shared/research/->/clearsin miedo - Plans -> Se guarda en
thoughts/shared/plans/-> Diseño iterativo sin llenar contexto - Implement -> Referencias el plan -> Contexto siempre < 60%
- Validate -> Comparas contra el plan -> Verificación sistemática
Qué soluciona:
- “¿Dónde guardé esa info?” -> Todo en
thoughts/shared/, siempre accesible - “¿Por qué decidimos esto?” -> Cada decisión tiene su research o plan asociado
- “Nuevo en el equipo” -> Lee
shared/y entiendes el proyecto - “Investigar de nuevo” -> Si está en
thoughts/, no se reinvestiga
Pero sobre todo, ahora Claude Code sigue tu CLAUDE.md de forma consistente porque el contexto nunca se llena.
No vas a ir más rápido, pero ahora tienes el control del contexto automático en tu flujo de trabajo.
Referencias
Sobre Context Engineering
- Advanced Context Engineering for Coding Agents - Dex Horthy
- Frequent Intentional Compaction - HumanLayer
- Writing a Good CLAUDE.md - HumanLayer
- I Mastered the Claude Code Workflow - Ashley Ha
- Context Engineering SF: Advanced Context Engineering for Agents
- Avoiding Skill Atrophy in the Age of AI
- Effective context engineering for AI agents - Anthropic
- 12-Factor Agents - Own your context window